In the cloud computing environment: efficiency wins. Hyperscalers make money from renting you resources on a time-basis; the fewer resources and less time your workload requires, the lower the cost. A Lambda function which runs in 1 second compared to 5 seconds is going to cost 80$ less. At small scales this is often inconsequential but with sufficient volume it makes a big difference. For example, at 1 invocation per second the longer function costs ~$431/month compared to ~$81/month.
I have been working on a project exploring new and novel use-cases for Apache
Parquet, the file format which underscores the
Delta Lake storage protocol.
My work uses .parquet files smaller than 50MB in size and ultimately
latency is the biggest concern. When retrieving data from any data
service there is always a fixed cost of overhead regardless of the data
transferred. Retrieving a 1MB object or a 1GB object still requires locating
and loading the data from storage, validating authentication
credentials/headers, and then constructing a request stream.
Working in this domain I have discsussed challenges with Andrew Lamb who has been doing similarly interesting explorations at InfluxData. His work builds on what he and Raphael outlined in their 2022 post: Querying Parquet with Millisecond Latency
Meanwhile Databricks also released Lakebase which I am confident is also utilizing Apache Parquet for similar retrieval patterns for their PostgreSQL engine.
Somewhere way down the data stack we are all trying to squeeze as much out of Parquet and S3 as possible.
Because of my work on the
delta-rs project, I am quite familiar
with the Parquet file
format
and the ways in which it can be read and written.
I need to read .parquet files in an exremely low-latency
environment with worst-case performance around the 100ms mark. I picked up two
foundational dependencies of delta-rs: the
parquet and
object_store crates, and dove into the Parquet file format:
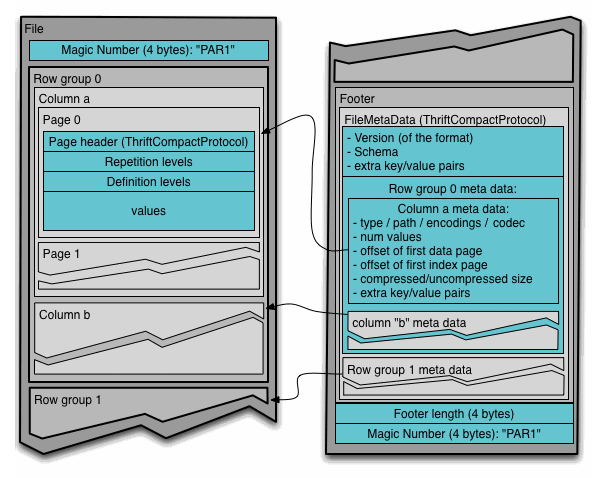
The .parquet file has a “footer” which contains practically all the useful
metadata for understanding the file, with the last eight bytes indicating the
length of the footer. This is largely useless trivia until you learn that most
object stores like AWS S3 allow for Range headers on the
GetObject
call with a negative byte range. For a large .parquet file you can retrieve
Range: -8 bytes and that would tell you the footer length, which you could
then fetch with Range: -<footer length>, and then you would be able to
understand practically everything about the file! Those Range requests would
even allow you to fetch individial row groups, a hugely beneficial
performance optimization when working with large .parquet files.
Fortunately for everybody, this is exactly what
ParquetObjectReader
does! From the perspective of the underlying ObjectStore implementation the call flow is:
get_optse(Range(-8))get_opts(Range(-<footerlen>))get_ranges(*row-groups)
For large .parquet files, hundreds of MBs or GBs, this approach works very
well for most processing engines where less data neding to be deserialized and processed
means tangible performance gains. In fact, I have it on good authority that
this approach is how the Databricks Photon engine’s predictive
I/O squeezes
even more query performance out of Apache Parquet.
For me however each request to S3 in the list above has roughly 30ms overhead and they must be executed sequentially which means 3 requests has a worst-case scenario of 90ms.
Hinting at a rough approximation of footer size can prevent one of the two calls, bringing the worst-case down ot 60ms. Accessing relevant data in under 70-80ms is good but not great.
Andrew and Raphael’s blog post Querying Parquet with Millisecond Latency is full of useful approaches for reducing query and processing time. At some point however you hit the wall of fundamental performance overhead of the object store itself.
I have hit that wall.
The options available in front of me are:
- consider novel data structures inside the Parquet file
- secondary indices outside of the Parquet file
- ggressive caching strategies.
I’m not thrilled with any of them, though I have already utilized hacks from #1 with Parquet data layout changes.
As frustrating as a problem that might genuinely be unsolveable might be, it has been a lot of fun discussing strategies with folks at cloud providers, other companies, and in the open source community on how to squeeze every last bit of performance out of Apache Parquet and cloud storage.
I might have to make peace with 60ms of latency, but not just yet.
]]>