One of the first pain points many organizations endure when scaling Jenkins is
the rapid accumulation of artifacts on their master’s filesystem. Artifacts
are typically built packages such as .jar, .tar.gz, or .img
files, which are useful to persist after a Pipeline Run has completed for later
review as necessary. The problem that manifests over time, is quite
predictable, archived artifacts incur significant disk usage on the master’s
filesystem and the network traffic necessary to store and serve the artifacts
becomes a non-trivial problem for the availability of the Jenkins master.
Perhaps one of my “favorite” (read: not my favorite) responses from the “Not Actually Helpful Brigade” to questions or concerns about scaling artifact storage on the Jenkins mailing list is something along the lines: “Archived artifacts aren’t supposed to be used like that, you should really be using Artifactory or Nexus.”
Not. Actually. Helpful.
One of my number one pet-peeves with any piece of software is when people tell me that I’m using it wrong. No. If I’m not supposed to use Jenkins in this fashion, and Jenkins doesn’t prevent me from doing so, that’s a bug in Jenkins, full stop.
While discussing this a bit with my crazy-idea co-conspirator Jimbo, I came to a delightfully devious idea: what if I could transparently make artifact archival external to Jenkins?
Traditionally in Jenkins people solve problems with plugins. I hate plugins. I hate to write them. I hate managing their N-different upgrade lifecycles in Jenkins environments I maintain. I hate that “write a plugin” is the de-facto answer given to many who wish to do interesting things in Jenkins.
I do, however, love Jenkins Pipeline. I love writing Jenkins Pipeline. I love
that I can put Jenkins Pipelines in a Jenkinsfile and check it into my source
repo. I love that I can do many interesting things with Jenkins via Pipelines.
Implementing crazy things
Pipeline provides two steps, archive which was deprecated against all
sensible logic, and archiveArtifacts which does the exact same thing with
more arguments and verbosity. Starting with the overriding built-in
steps pattern, which I
discussed last August, I set about re-implementing these two steps in a Shared
Library
Part of the challenge with implementing a Pipeline Shared Library is that the Groovy code implemented in them executes within the Jenkins master JVM, whereas Pipeline steps execute within the Jenkins agent JVM. The consequence of this is that I cannot simply load a Java library which supports uploading files to Azure Blob Storage (for example) because when that code would execute, it would be executing inside the Jenkins master rather than the agent and therefore would not have access to the filesystem.
Approaching this problem from a slightly different angle: I need to be able to
get “my” Pipeline Shared Library code to execute on the agent in order to
have access to the filesystem. Reaching into my Pipeline bag of tricks, which
looks suspiciously similar to my Pipeline pit of despair, I grabbed the
built-in libraryResource step which can “Load a resource file from a shared
library.” The following snippet of (Scripted Pipeline) code will allow me to drop code onto an
agent for execution:
String uploadScript = libraryResource 'io/codevalet/externalartifacts/upload-file-azure.sh'
writeFile file: 'my-special-script', text: uploadScript
sh 'bash my-special-script'
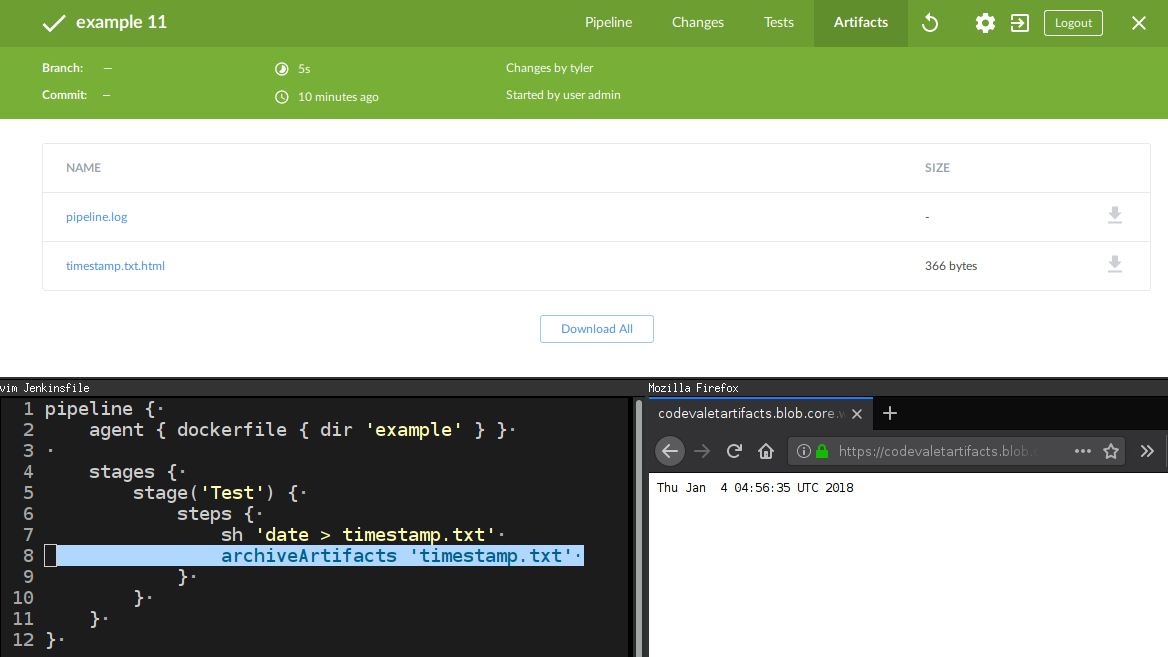
Overriding archiveArtifacts is only half of the solution however, from the
web UI in Jenkins, end-users should still be able to access the archived
artifacts.
Included in my
override
is code which will generate an HTML file with a redirect to the artifact in
Azure, and use the actual built-in archiveArtifacts to store that.
Presently I don’t have a more elegant solution for a “artifact pointer” but I’m
sure that could be solved via an actual plugin :).
By defining some environment variables and credentials at an administrative level, to indicate where artifacts should be stored, and by using the “Load Implicitly” pattern discussed in the overriding built-in steps blog post, I can override the artifact archival for end-users in my Jenkins environment.
Future work
My current work-in-progress
relies on a crazy Bash script for uploading files to Azure, which means it has
some system dependencies and does not work on Windows. I plan to work around
this by implementing the artifact upload with Go and embedding Go binaries in
the Shared Library for delivery with libraryResource.
The other bit of future work I would like to implement is unarchive, which is
actually a real built-in step in Pipeline, but doesn’t seem to actually be
usable in any tangible sense. There are some cross-Pipeline use-cases for
“unarchiving” an artifact for re-use, which is currently not well supported in
Pipeline.
Another potential area of exploration would be overriding stash and unstash
steps to use this external artifact storage mechanism to avoid some of the
Remoting performance penalties which
are associated with larger stashes.
Conclusion
. After a night of fervent hacking on this experiment, I cannot yet confidently state whether it’s a terrible or brilliant idea. I do think this approach has the potential to be an “easy win” for making Jenkins more scalable, without requiring significant surgery in Jenkins core or the surrounding plugins.
Assuming this pattern has potential, I can imagine it being trivial to support S3, Azure Blob Storage, Swift, and any number of other storage backends. If they can be supported via a simple Go program, then why not!